

Выполнили очередное масштабное обновление гео-кодера для адресов России. В нашем гео-кодере в основном используются данные, которые мы извлекаем из открытой карты OpenStreetMap. В дополнение к этой карте подключили ещё один источник гео-данных на основе информации, предоставленной нашими пользователями. Это позволило более чем в два раза повысить частоту, с которой Ахантер возвращает координаты с детализацией до дома.
Также в рамках данного обновления были доработаны алгоритмы гео-кодирования. В предыдущей версии при отсутствии детализированных координат для дома, указанного в адресе, Ахантер возвращал координаты середины улицы, на которой расположен этот дом. В новой версии реализовали приближённую оценку для несуществующих координат дома на основе координат его соседей. Сейчас в таких ситуациях Ахантер отыскивает на карте несколько соседних домов, после чего выполняет по ним интерполяцию координат искомого дома.
Дополнительно доработали алгоритмы определения координат для устаревших адресов. Раньше Ахантер не всегда возвращал координаты домов, принадлежащих устаревшим адресам. Исправили эту недоработку, теперь наш сервис старается для таких адресов тоже выдавать координаты с детализацией до дома, в случае, если у устаревшего адреса есть современные альтернативы. Это удаётся сделать, если адрес и соответствующее ему здание не прекратили своё существование окончательно, т.е. дом не был снесён и населённый пункт не был заброшен, а например, если произошло объединение улиц, а также переподчинение или поглощение населённого пункта соседним городом.
В Ахантере есть две функции, связанные с получением данных о юридических лицах, находящихся в открытом доступе в реестре ЕГРЮЛ. Функция подсказок suggest/company и функция получения полных сведений о юридическом лице fetch/company.
С помощью подсказок можно быстро находить нужную компанию по названию, юридическому адресу, ИНН и прочим реквизитам. Эта функция в Ахантере примечательна тем, что работает в реальном времени. Примерно так, как показано ниже.
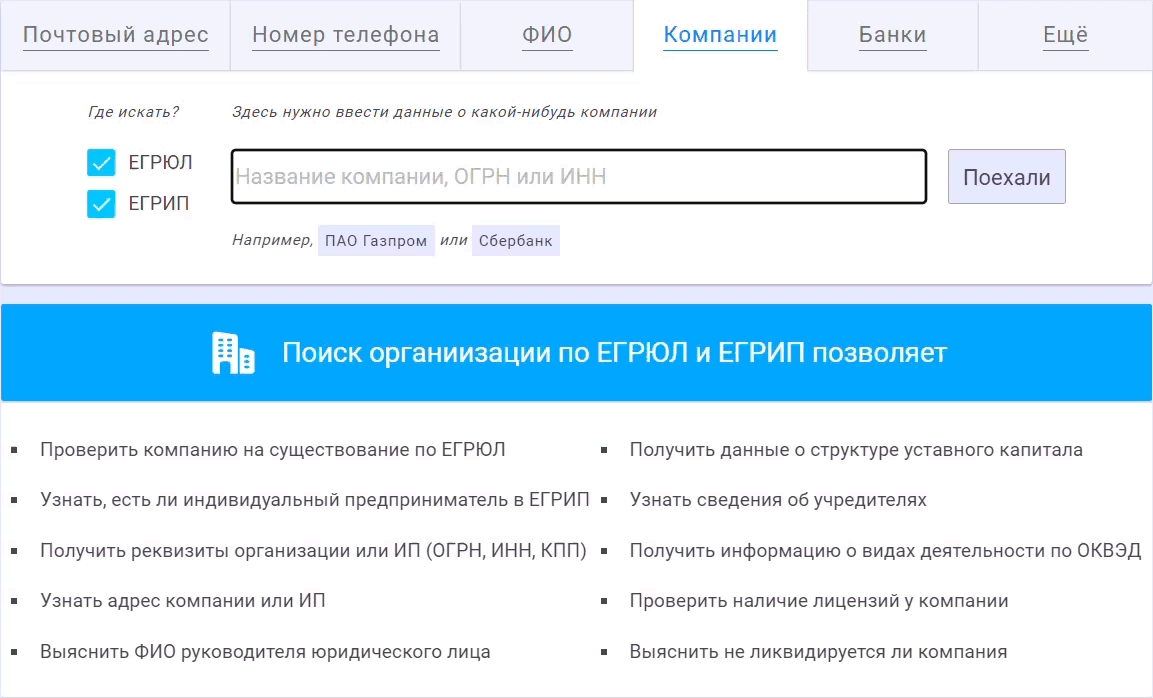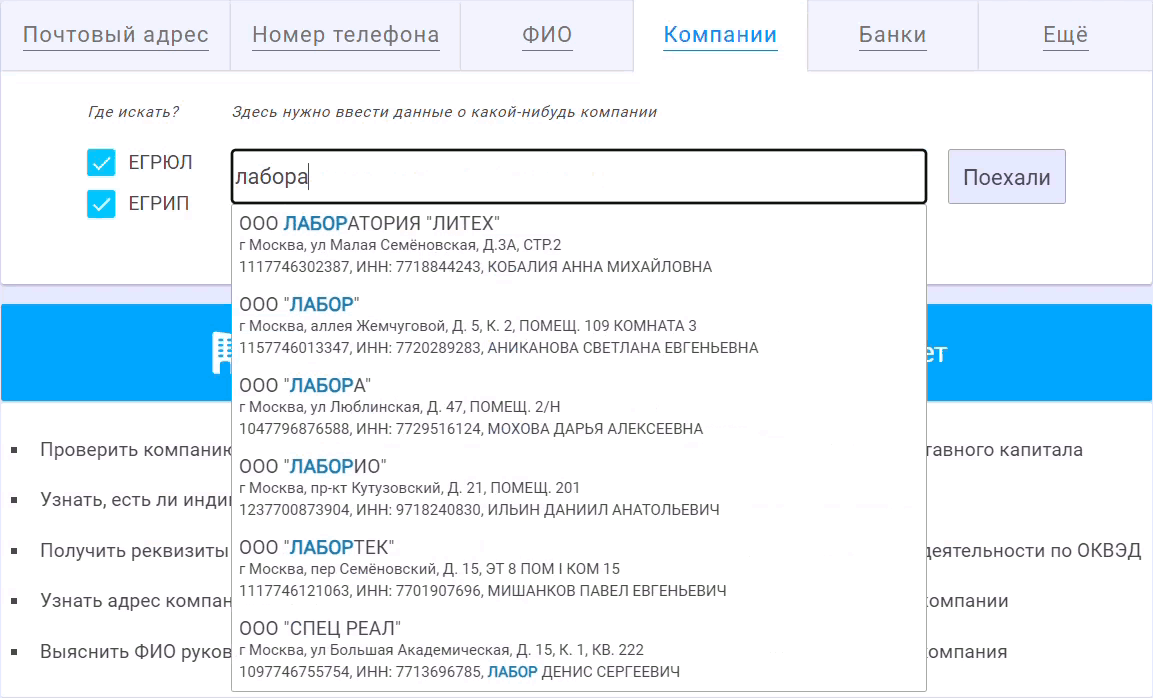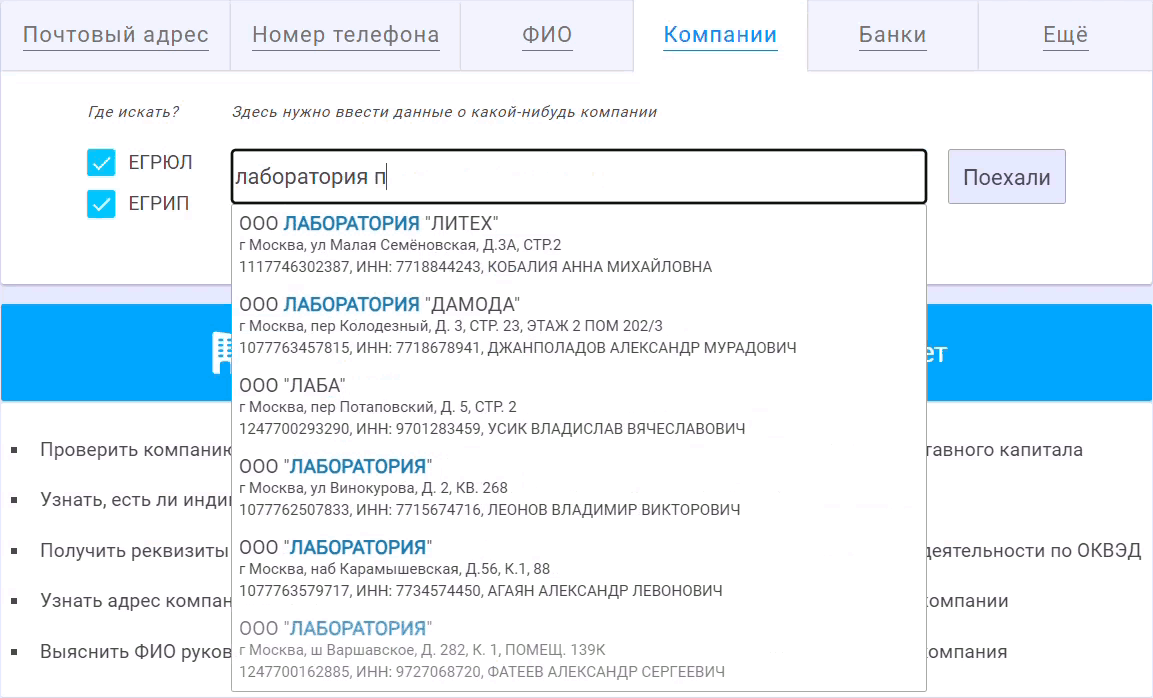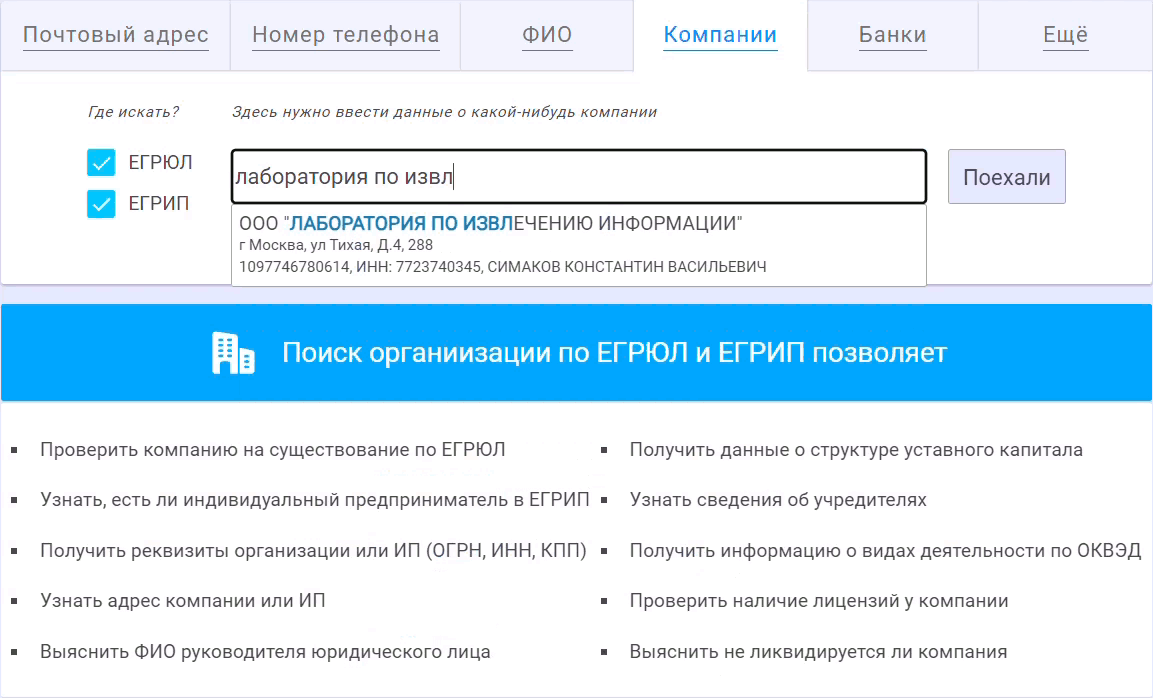
Самое сложное в таком функционале - с одной стороны сделать его быстрым, чтобы поиск в многомиллионной базе юридических лиц происходил мгновенно, за считанные миллисекунды. С другой стороны, поиск должен быть максимально релевантным, т.е. угадывать искомую информацию по минимальному числу введённых символов.
Это достигается за счёт правильного ранжирования, чтобы в топ найденных компаний попадали наиболее вероятные. Когда пользователь вводит очередную букву искомой компании, Ахантер выполняет новый поиск в базе ЕГРЮЛ и ранжирует найденный список, чтобы на его вершину попали только наиболее подходящие. В рамках доработки мы переделали алгоритм этого ранжирования. Теперь Ахантер учитывает размер компании, популярность места её нахождения, а также значимость тех или иных слов вводимого названия.
В рамках доработки функции fetch/company добавили в выдачу информацию о юридическом адресе компании, в том виде, в котором этот адрес представлен в ЕГРЮЛ. Раньше мы выдавали его только в стандартизированном виде, который предлагает Ахантер, а также в виде неформализованной строки. Оказалось, для некоторых CRM важно также иметь юридический адрес в исходном виде по ЕГРЮЛ. Например, это нужно при включении адреса в юридически значимый электронный документ в рамках ЭДО. Сейчас такая опция включается в API при использовании параметра output=cfulladdr.
С помощью данной опции теперь можно дополнительно запросить у Ахантера исходный юридический адрес по ЕГРЮЛ и включить его в электронный документ перед подписанием цифровой подписью.
24.09.2025 В гео-кодере Ахантера увеличили число детализированных ответов до дома в два раза
20.03.2025 Доработали подсказки по ЕГРЮЛ, расширили информацию об адресе компаний
19.12.2017 Обновили структуру классификатора адресов РФ.
21.09.2017 Внедрили машинное обучение в детекторе ФИО.
20.06.2017 Переделали геокодер и внедрили новую версию на ahunter.ru.
27.01.2017 Запустили в боевом режиме ahunter.ru версии 3.0.
30.11.2016 Запустили в режиме апробации репликацию данных между серверами Ахантера.