
 При обновлении базы гео-кодера переработали технологию обучения извлекателя адресных данных с карты. Основная проблема пополнения координатной базы Ахантера на основе открытых картографических данных заключается в том, что на карте, как правило, представлено много информации, которая не имеет отношения к почтовым адресам. Например, на карту наносятся тропинки, реки, водоёмы и даже фонарные столбы. В наших задачах важно собрать с карты только координаты тех объектов, которые используются в почтовой адресации, например, координаты городов, улиц и домов.
При обновлении базы гео-кодера переработали технологию обучения извлекателя адресных данных с карты. Основная проблема пополнения координатной базы Ахантера на основе открытых картографических данных заключается в том, что на карте, как правило, представлено много информации, которая не имеет отношения к почтовым адресам. Например, на карту наносятся тропинки, реки, водоёмы и даже фонарные столбы. В наших задачах важно собрать с карты только координаты тех объектов, которые используются в почтовой адресации, например, координаты городов, улиц и домов.
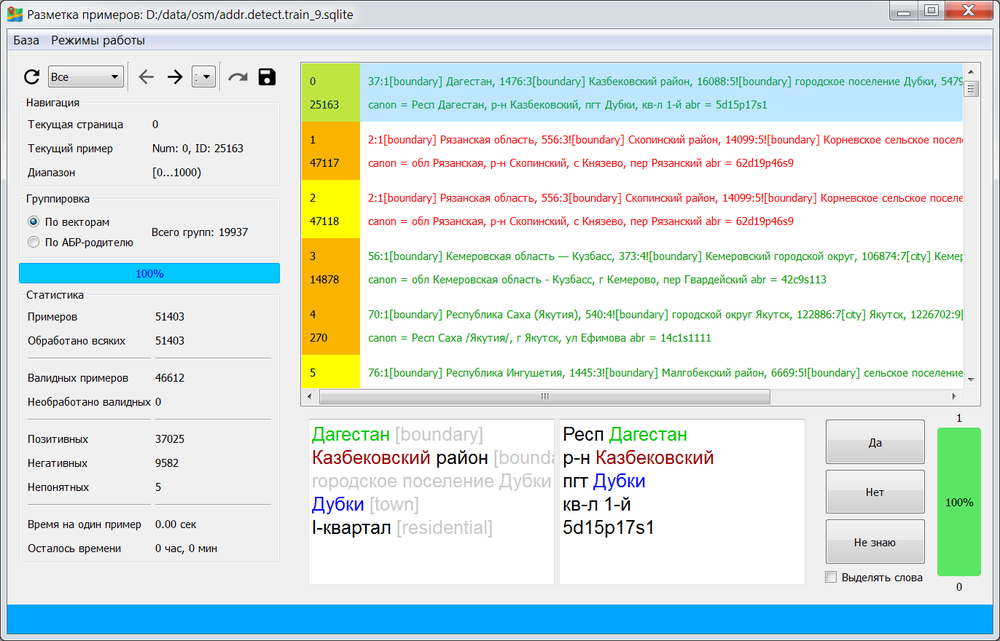
Сбор именно такой, полезной для наших целей, информации у нас выполняет обученный ИИ-алгоритм. На данный момент этот алгоритм обучен на ~80 тысячах обучающих примеров, с помощью которых ему объяснили, какие данные с карты собирать нужно, а какие следует откидывать. Каждый раз, когда мы заново запускаем механизм сбора и обновления базы гео-кодера мы стараемся дополнительно пополнить и эту обучающую выборку, поскольку со временем на карте могут появляться новые способы описания интересующих нас объектов, а также - новые способы описания объектов, которые нам не интересны. К первой категории относятся позитивные примеры, а ко второй - негативные.
Очередное пополнение обучающей выборки сопряжено с трудностями, обусловленными человеческим фактором. Когда эксперт добавляет очередной позитивный обучающий пример, он вполне может не знать, что ранее другой эксперт отнёс похожий пример к противоположной категории негативных примеров. Так в обучающей выборке возникают конфликты и ошибки, из-за которых обученный ИИ-алгоритм начинает себя вести неадекватно. С ростом обучающей выборки число таких конфликтов неуклонно растёт, поэтому возникает задача технологического контроля и верификации экспертной деятельности.
Для этих целей мы разработали продвинутый инструмент, помогающий эксперту непосредственно в процессе разметки принимать правильные решения, не конфликтующие с решениями других экспертов на похожих данных. Этот инструмент анализирует в реальном времени деятельность эксперта при подготовке очередного обучающего примера, оценивает его похожесть на уже имеющиеся примеры, подготовленные ранее, и даёт оценку вероятности отнесения каждого нового примера к категории позитивных и негативных. Если мнение эксперта расходится с мнением этого механизма, эксперт может посмотреть на группу похожих примеров и скорректировать разметку.
С помощью данной технологии мы смогли нарастить обучающую базу на 25%, потратив на это в пять раз меньше экспертного времени, в сравнении с предыдущими итерациями по обновлению гео-кодера. Обученный на обновлённой базе ИИ-алгоритм мы применили к свежей OSM-карте, в результате смогли нарастить базу гео-кодера на дополнительные 10%. Обновлённая база гео-кодера уже доступна и используется в облачной версии Ахантера.
 Запустили сервис, позволяющий по ФИАС-идентификатору получить соответствующий почтовый адрес. Основная задача Ахантера при обработке почтовых адресов заключается в приведении адреса, записанного одной строкой, к структурированному виду, в котором были бы отдельно выделены адресные поля, такие как название города, улицы, номер дома и т.д. Это сложная задача, поскольку подразумевает обработку исходных данных, записанных без соблюдения строгих правил и стандартов. К тому же адрес в исходном виде может содержать опечатки или неточности.
Запустили сервис, позволяющий по ФИАС-идентификатору получить соответствующий почтовый адрес. Основная задача Ахантера при обработке почтовых адресов заключается в приведении адреса, записанного одной строкой, к структурированному виду, в котором были бы отдельно выделены адресные поля, такие как название города, улицы, номер дома и т.д. Это сложная задача, поскольку подразумевает обработку исходных данных, записанных без соблюдения строгих правил и стандартов. К тому же адрес в исходном виде может содержать опечатки или неточности.
Вместе с этим пользователи сервиса иногда сталкиваются с противоположной задачей, когда по известному идентификатору адреса выполняется его простой поиск в базе сервиса и возвращается соответствующий ему почтовый адрес. Эта задача возникает нечасто, т.к. конечные пользователи изначально обычно не располагают именно ФИАС-идентификаторами своих адресов. Часто пользователи даже не знают точно почтового индекса. Тем не менее, такая задача возникает, когда требуется актуализировать сведения о ранее стандартизованном адресе. В этом случае нет необходимости обрабатывать полноценно адрес снова, достаточно запросить свежие данные о нём, такие как координаты и коды по справочникам, передав сервису его идентификатор.
Для этих целей мы включили в Ахантер сервис обратного поиска, который позволяет по ФИАС-идентификатору найти любой адресный объект, зарегистрированный в ФИАС. Поддерживается поиск как для адресообразующих элементов ФИАС, таких как города и улицы, а также поиск для домов, земельных участков и квартир. Сервис доступен через API, описание которого доступно здесь. Также получить адрес по ФИАС-идентификатору можно в разделе Демо.
 Добавили в Ахантере возможность проверить существование квартиры, указанной в почтовом адресе. Когда наш сервис выполняет стандартизацию адреса, он отдельно выделяет в исходном адресе номер дома, корпуса, строения и квартиры. Эти компоненты затем дополнительно проверяются на существование в ФИАС. Такая проверка позволяет дополнительно удостовериться в правильности адреса, поскольку нахождение дома и/или квартиры в ФИАС даёт больше гарантий того, что адрес реально существует.
Добавили в Ахантере возможность проверить существование квартиры, указанной в почтовом адресе. Когда наш сервис выполняет стандартизацию адреса, он отдельно выделяет в исходном адресе номер дома, корпуса, строения и квартиры. Эти компоненты затем дополнительно проверяются на существование в ФИАС. Такая проверка позволяет дополнительно удостовериться в правильности адреса, поскольку нахождение дома и/или квартиры в ФИАС даёт больше гарантий того, что адрес реально существует.
Ранее Ахантер выполнял проверку только для домов, корпусов и строений. Это было связано с тем, что в базе ФИАС информация о квартирах была представлена недостаточно полно. Из-за того, что многие квартиры в реальных многоквартирных домах в ФИАС отсутствовали, эффективность проверки квартир с помощью такого справочника оставляла желать лучшего.
Однако к настоящему моменту в ФИАС зарегистрировано уже более 50 млн. квартир, поэтому мы решили использовать эти данные в Ахантере для более точной валидации почтовых адресов при их обработке.
В новой версии сервиса был расширен состав хранилища, куда мы добавили все имеющиеся в ФИАС номера квартир с привязкой к конкретным домам, а также их справочные коды по ФИАС и ГАР. Основная проблема такого расширения связана с существенным увеличением размеров хранилища сервиса, которое негативно влияет на производительность сервиса. Производительность важна, т.к. Ахантер в облаке ежесуточно обрабатывает до 1 млн. запросов в режиме реального времени. Замедление обработки этих запросов из-за увеличения времени доступа к разросшемуся хранилищу сервиса может приводить к отказу в обработке и временной недоступности сервиса.
Чтобы исключить данные эффекты нам пришлось серьёзно поработать над оптимизацией нового хранилища. Для этих целей были разработаны новые методы сжатия справочных данных о квартирах, а также реализованы методы кэширования, позволяющие минимизировать дисковые операции при обработке пользовательских запросов.
 Ахантер прошёл полноценную экспертизу на соответствие требованиям реестра отечественного программного обеспечения. В результате данной экспертизы наш продукт был включён в данный реестр, его карточку с информацией можно посмотреть здесь.
Ахантер прошёл полноценную экспертизу на соответствие требованиям реестра отечественного программного обеспечения. В результате данной экспертизы наш продукт был включён в данный реестр, его карточку с информацией можно посмотреть здесь.
Изначально Ахантер разрабатывался с минимальным количеством зависимостей от стороннего ПО. Например, Ахантер хранит все справочники и индексы в собственной системе хранилищ, не привлекая для этого сторонние СУБД. Многие стандарты в Ахантере также реализованы с нуля без использования сторонних компонентов, например, это касается стандартов JSON и XML. Это позволяет сократить зависимость программного кода от стороннего ПО, что в свою очередь упрощает перенос и адаптацию продукта на другие платформы. Благодаря такой архитектуре, несколько лет назад мы без ощутимых сложностей смогли собрать и запустить сервис на платформе HP-UX на базе процессоров Intel Itanium 2.
В рамках текущих работ по адаптации под требования реестра отечественного ПО мы собрали и запустили наш продукт на платформе Astra Linux, поскольку запуск и работа под управлением отечественной ОС является одним из требований для включения в реестр. По своим качествам Ахантер под Astra Linux является полным аналогом остальных Linux-сборок в таких дистрибутивах как Red Hat, CentOS и Ubuntu.
Адаптация Ахантера к отечественной платформе и включение в реестр отечественного ПО позволяют внедрять и использовать наш продукт, в том числе, и в инфраструктурах государственных заказчиков.
 В проектах, где требуется искать и извлекать из текстов целевые данные, мы используем правила распознавания и извлечения. Такие правила чем-то похожи на регулярные выражения, но применяются не к символьным строкам, а к текстам, разбитым на слова, словосочетания и другие сущности. Эти правила описываются на особом языке и обрабатываются соответствующим интерпретатором. Сами правила задают условия, которым должны удовлетворять куски текста, окружающие тот фрагмент, который нужно распознать и извлечь.
В проектах, где требуется искать и извлекать из текстов целевые данные, мы используем правила распознавания и извлечения. Такие правила чем-то похожи на регулярные выражения, но применяются не к символьным строкам, а к текстам, разбитым на слова, словосочетания и другие сущности. Эти правила описываются на особом языке и обрабатываются соответствующим интерпретатором. Сами правила задают условия, которым должны удовлетворять куски текста, окружающие тот фрагмент, который нужно распознать и извлечь.
Ранее для этих целей мы использовали XML-нотацию, разработанную и описанную много лет назад. Ознакомиться с ней можно здесь. За время использования этой модели в разных наших проектах накопился определённый опыт и желание расширить выразительные способности языка, чтобы появилась возможность более лаконично и точно описывать извлекаемые фрагменты и их текстовое окружение.
Мы переработали язык правил извлечения, вместо XML реализовали его в Си-подобном синтаксисе. Добавили возможность описывать библиотеки правил, вызывать одни правила в теле других правил по аналогии с процедурными языками. Также добавили возможность накладывать ограничения на свойства конкретных слов текста с помощью логических выражений неограниченной сложности. Кроме этого в правилах добавили такие аналоги возможностей языка регулярных выражений, как look-ahead и look-behind конструкции. С помощью них можно задавать явные запреты на контексты до и после фрагмента, накрываемого правилом.
Наравне с жадными и ленивыми квантификаторами добавили поддержку умных квантификаторов для ограниченного и неограниченного числа повторов. Умные квантификаторы самостоятельно определяют момент, когда следует закончить повторять применение текущего условия правила и переходить к следующему.
Новый движок внедрили вместо старого во внутренние процессы компании, в которых выполняется извлечение данных из открытых источников для пополнения эталонных справочников, на основе которых работает Ахантер. Также новый движок внедрили в самом Ахантере, в алгоритмах, где требуется распознавать типовые конструкции в составе почтовых адресов, такие как номера домов и квартир, а также типовые конструкции в записях с номерами телефонов.
03.05.2026 Добавили поиск по КЛАДР-кодам и ускорили префиксный поиск при стандартизации адресов
03.03.2026 Переработали пространственный индекс для ускорения обратного гео-кодера
13.03.2008Симаков Константин защитил диссертацию на соискание ученой степени кандидата технических наук.
09.03.2008На сайте запущен раздел "Отзывы", оставляйте свои вопросы и предложения.
01.03.2008Web-сервер запущен в работу!
29.02.2008Разработан backend Web-сервер. Выполнены тестовые запуски и нагрузочное тестирование.
22.02.2008Разработан дизайн Web-сайта.
15.02.2008Подготовлена аппаратная часть для работы backend Web-сервера.
01.02.2008Проведен тестовый запуск frontend Web-сервера.